This post contains my notes from an old version of IPX Class on Demand by Joe Astorino.
RD has no special meaning—it is only used to make potentially overlapping IPv4 addresses globally unique
Route Targets are additional attributes attached to VPNv4 BGP routes to indicate VPN membership
Export Route Targets identifying VPN membership are appended to customer route when it is converted into VPNv4 route
RD & RT are extended BGP communities; neighbor send-community extended is required!
RR for VPNv4 does not need to be the same as RR of IPv4.
PE imposes 2 labels, the one if from LDP, and the bottom one is from VPNv4 address-family.
Each bgp address-family is a different RIB.
- Import policy means that routes will come from the VPN extended community
- Export policy means that routes will go to the VPN extended community
ARF –Automatic Route Filtering: Only VPN information matching a locally configured RT will be imported
Could be disabled: no default bgproute-target filter
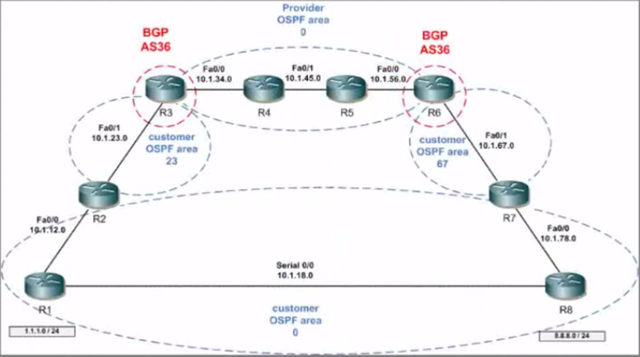
By default, when running OSPF over Frame-Relay and network type is anything except point-to-multipoint, on a spoke, the nexthop for a route originated from another spoke will be that spoke.
But when the network type is point-to-multipoint, the nexthop will be the hub, and a host route for each spoke will exist.
So make sure to use point-to-multipoint when using MPLS.
RIP/EIGRP address-family version and summarization is different form the RIP/EIGRP’s itself.
When the customer needs the same AS on multiple sites, the AS Override feature should be triggered. So the PE will override its (prepend). Another way to handle this requirement is using allowas-in. Continue reading “IPExpert CoD: MPLS-VPN”